Data Pipelines And Evolution of ETL vs ELT
In the era of big data, organizations are increasingly relying on data pipelines to manage, process, and analyze vast amounts of information. Data pipelines are automated systems that facilitate the flow of data from various sources to destinations, ensuring that data is cleaned, transformed, and stored efficiently. This article explores the fundamentals of data pipelines, their components, and their significance in modern data architecture.
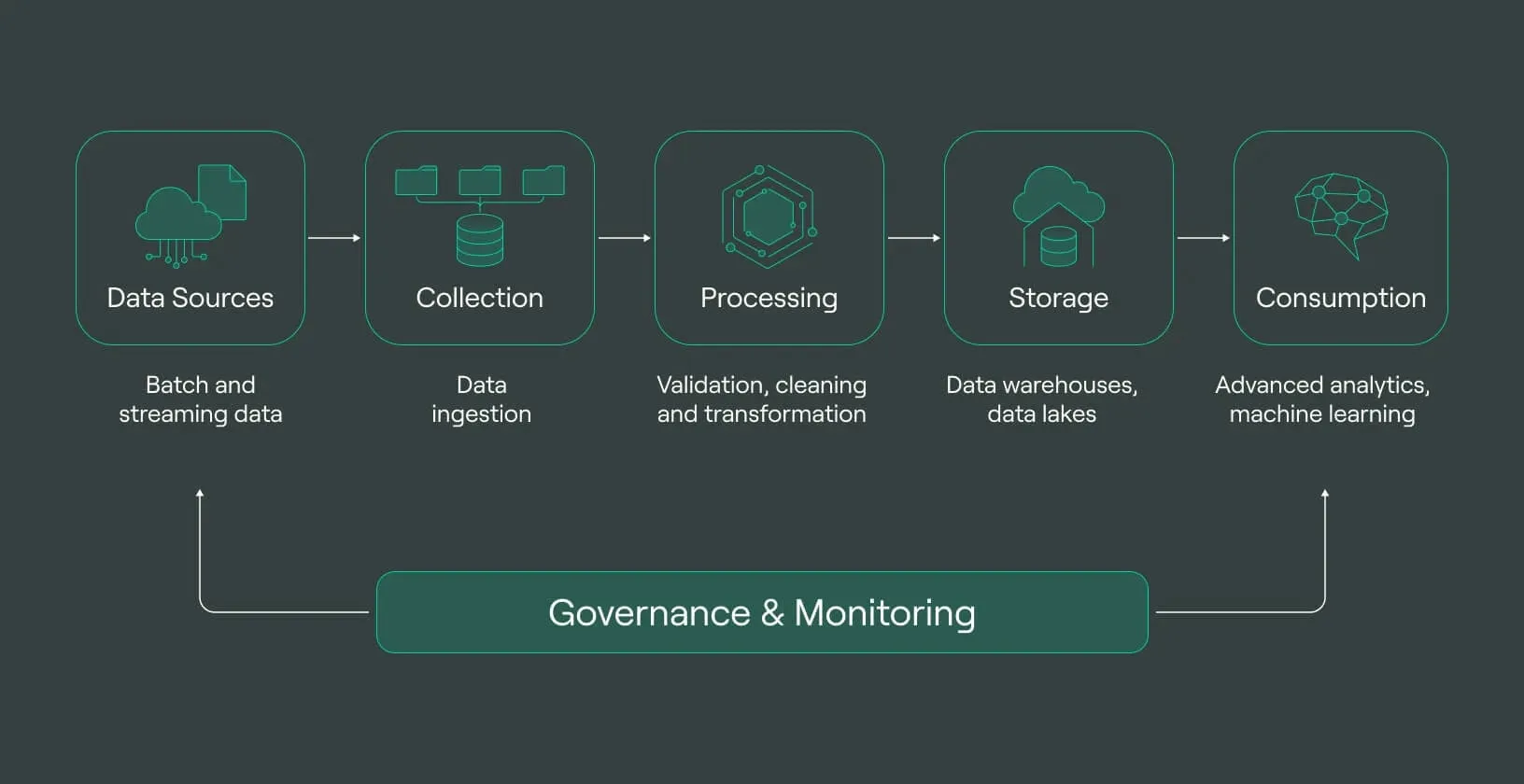
What is a Data Pipeline?
A data pipeline is a series of steps that data goes through from its origin to its final destination. These steps typically include data extraction, transformation, and loading (ETL), but can also encompass data ingestion, processing, and analysis. Data pipelines are designed to automate these processes, making them more efficient and reliable.
Components of a Data Pipeline
-
Data Sources: The starting point of any data pipeline is the data source. This could be databases, APIs, files, or streaming data from IoT devices.
-
Data Ingestion: This is the process of collecting data from various sources. Data ingestion tools like Apache Kafka, Apache NiFi, and AWS Kinesis are commonly used for this purpose.
-
Data Transformation: Once data is ingested, it often needs to be transformed to fit the desired format or structure. This can include cleaning data, normalizing it, or aggregating it. Tools like Apache Spark, Talend, and Informatica are popular for data transformation.
-
Data Storage: Transformed data is then stored in a database or data warehouse. Common storage solutions include Amazon S3, Google BigQuery, and Snowflake.
-
Data Processing: This involves analyzing the data to derive insights. Data processing can be done in real-time (stream processing) or in batches (batch processing). Tools like Apache Flink and Apache Beam are used for stream processing, while Apache Hadoop is used for batch processing.
-
Data Visualization: The final step is to present the data in a meaningful way. Tools like Tableau, Power BI, and Looker are used for data visualization.
Types of Data Pipelines
-
Batch Data Pipelines: These pipelines process data in batches at scheduled intervals. They are suitable for large volumes of data that do not require real-time processing.
-
Streaming Data Pipelines: These pipelines process data in real-time as it arrives. They are ideal for applications that require immediate data analysis, such as fraud detection or real-time analytics.
-
Hybrid Data Pipelines: These combine elements of both batch and streaming pipelines, offering flexibility for different types of data processing needs.
Benefits of Data Pipelines
-
Automation: Data pipelines automate the data flow, reducing manual intervention and the risk of human error.
-
Scalability: They can handle large volumes of data and scale as the data grows.
-
Efficiency: By automating data processes, pipelines improve the efficiency of data management and analysis.
-
Reliability: Data pipelines ensure that data is consistently and accurately processed, making them reliable for critical business operations.
Challenges of Data Pipelines
-
Complexity: Building and maintaining data pipelines can be complex, requiring expertise in various tools and technologies.
-
Data Quality: Ensuring data quality throughout the pipeline is a significant challenge. Poor data quality can lead to inaccurate insights.
-
Security: Data pipelines must be secured to protect sensitive information from breaches and unauthorized access.
Technical Considerations For Data Pipelines
-
Orchestration Tools:
- Apache Airflow: An open-source platform to programmatically author, schedule, and monitor workflows.
- Luigi: A Python module that helps you build complex pipelines of batch jobs.
- Prefect: A modern workflow orchestration tool that focuses on dataflow programming.
-
Data Formats:
- JSON: Lightweight data interchange format that is easy for humans to read and write and easy for machines to parse and generate.
- Parquet: Columnar storage file format that is optimized for use with big data processing frameworks.
- Avro: Data serialization system that provides rich data structures, a compact, fast, binary data format, and a container file to store persistent data.
-
Monitoring and Logging:
- Prometheus: An open-source monitoring and alerting toolkit.
- ELK Stack (Elasticsearch, Logstash, Kibana): A powerful set of tools for searching, analyzing, and visualizing log data in real-time.
- Grafana: An open-source platform for monitoring and observability that provides rich visualization and alerting capabilities.
While data pipelines offer numerous benefits, there are several cautionary notes to consider when designing and implementing them:
-
Data Quality:
- Validation: Ensure that data is validated at every stage of the pipeline to maintain data quality.
- Consistency: Maintain consistency in data formats and structures to avoid discrepancies.
-
Security:
- Data Encryption: Encrypt data both in transit and at rest to protect sensitive information.
- Access Control: Implement robust access controls to prevent unauthorized access to data.
-
Scalability:
- Resource Management: Plan for scalability by managing resources efficiently and ensuring the pipeline can handle increased data volumes.
- Performance Monitoring: Continuously monitor the performance of the pipeline to identify and address bottlenecks.
-
Fault Tolerance:
- Error Handling: Implement comprehensive error handling to manage failures and ensure data integrity.
- Redundancy: Build redundancy into the pipeline to ensure continuous operation in case of failures.
-
Compliance:
- Regulatory Requirements: Ensure that the data pipeline complies with relevant regulations and standards, such as GDPR or HIPAA.
- Audit Trails: Maintain audit trails to track data lineage and ensure compliance.
-
Maintenance:
- Documentation: Document the pipeline thoroughly to facilitate maintenance and troubleshooting.
- Updates: Regularly update the pipeline to incorporate new data sources, technologies, and best practices.
-
Cost Management:
- Budgeting: Be aware of the costs associated with data storage, processing, and tools.
- Optimization: Optimize the pipeline to reduce costs without compromising performance.
ETL vs ELT
In the realm of data management, ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two fundamental processes used to integrate and prepare data for analysis. While both processes aim to move data from source systems to a target database or data warehouse, they differ in the order of operations and their suitability for different scenarios. This article explores the differences between ETL and ELT, their advantages, and the use cases for each.
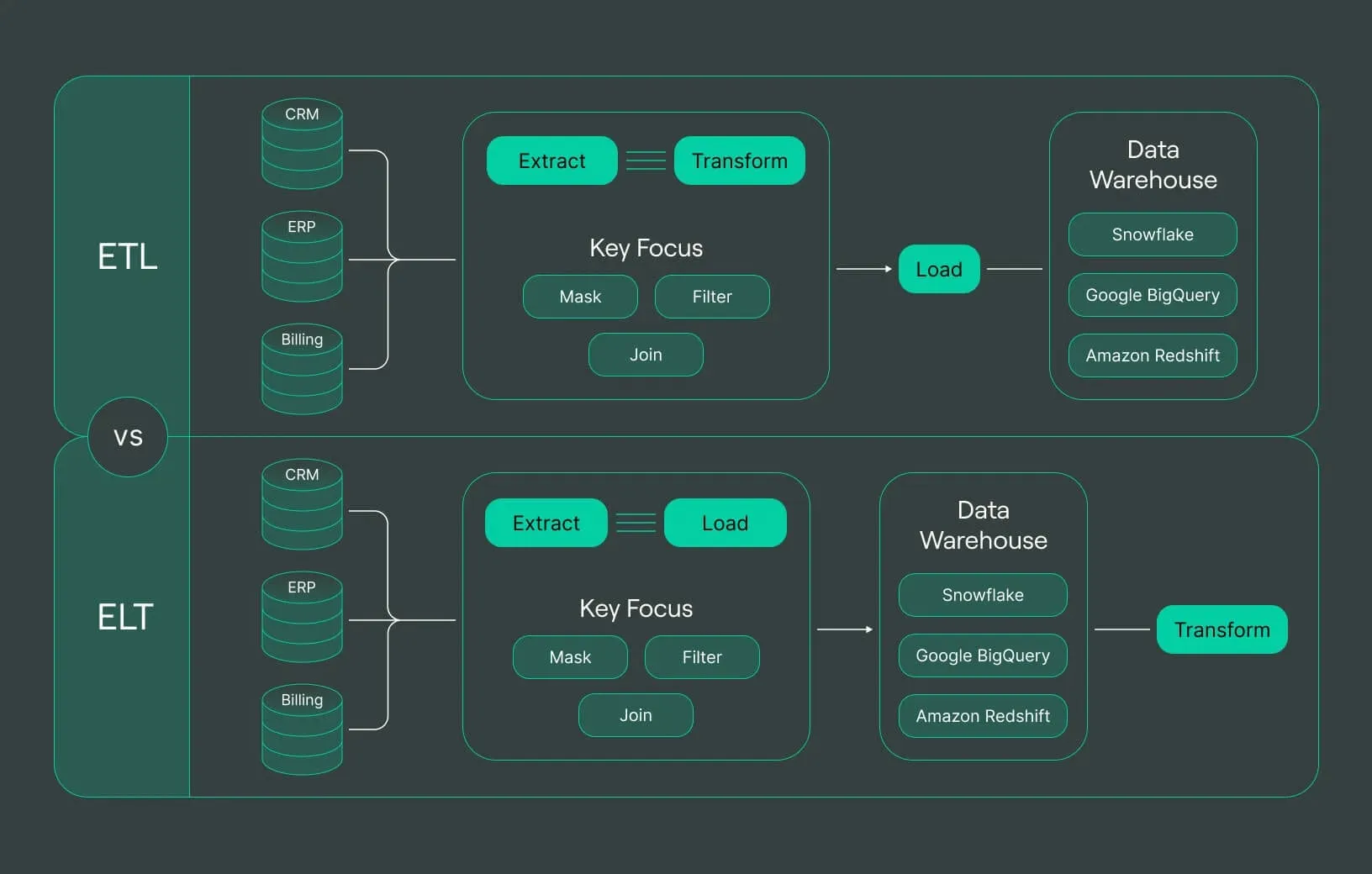
What is ETL?
ETL stands for Extract, Transform, Load. It is a traditional data integration process that involves three main steps:
-
Extract: Data is extracted from various source systems, such as databases, APIs, or files.
-
Transform: The extracted data is cleaned, normalized, and transformed to fit the desired format or structure. This step may include data validation, deduplication, and aggregation.
-
Load: The transformed data is loaded into the target database or data warehouse for storage and analysis.
Advantages of ETL
-
Data Quality: By transforming data before loading, ETL ensures that only clean and consistent data is stored in the target system.
-
Performance: Transforming data before loading can reduce the load on the target system, improving performance.
-
Flexibility: ETL allows for complex transformations and data enrichment before loading, making it suitable for scenarios requiring extensive data preparation.
Use Cases for ETL
-
Data Warehousing: ETL is commonly used in traditional data warehousing scenarios, where data from multiple sources is integrated and transformed before loading into a central repository.
-
Data Migration: When migrating data from legacy systems to new databases, ETL ensures that data is cleaned and transformed to fit the new schema.
-
Data Integration: ETL is suitable for integrating data from disparate sources, such as CRM, ERP, and marketing systems, into a unified data warehouse.
What is ELT?
ELT stands for Extract, Load, Transform. It is a modern data integration process that reverses the order of transformation and loading compared to ETL:
-
Extract: Data is extracted from various source systems.
-
Load: The extracted data is loaded into the target database or data warehouse in its raw form.
-
Transform: The loaded data is then transformed within the target system to fit the desired format or structure.
Advantages of ELT
-
Scalability: ELT leverages the processing power of modern data warehouses and cloud platforms, making it suitable for handling large volumes of data.
-
Simplicity: By loading raw data first, ELT simplifies the data integration process and reduces the need for complex transformations before loading.
-
Real-time Processing: ELT is well-suited for real-time data processing and analytics, as data can be loaded and transformed continuously.
Use Cases for ELT
-
Big Data Analytics: ELT is ideal for big data scenarios, where large volumes of data need to be processed and analyzed in real-time.
-
Cloud Data Warehousing: ELT is commonly used in cloud data warehousing solutions, such as Amazon Redshift, Google BigQuery, and Snowflake, which offer powerful data processing capabilities.
-
Data Lake Architectures: ELT is suitable for data lake architectures, where raw data is stored in a central repository and transformed as needed for analysis.
ETL vs ELT: Key Differences
-
Order of Operations: ETL transforms data before loading, while ELT loads data first and then transforms it.
-
Processing Power: ETL relies on the processing power of the source systems or intermediate servers, while ELT leverages the processing power of the target data warehouse or cloud platform.
-
Data Volume: ETL is suitable for smaller to medium-sized data volumes, while ELT is designed to handle large-scale data processing.
-
Complexity: ETL requires more complex data transformation processes before loading, while ELT simplifies the data integration process by loading raw data first.
Technical Considerations For ETL vs ELT
-
ETL Tools:
- Talend: An open-source data integration platform that supports ETL processes.
- Informatica: A comprehensive data integration platform that offers robust ETL capabilities.
- Pentaho: An open-source business intelligence and data integration platform.
-
ELT Tools:
- Google BigQuery: A fully-managed, serverless data warehouse that enables ELT processes by leveraging its powerful querying and processing capabilities.
- Snowflake: A cloud-based data warehousing solution that supports ELT by allowing data to be loaded first and then transformed within the platform.
- Amazon Redshift: A fast, fully managed data warehouse service that makes it simple and cost-effective to analyze all your data using standard SQL and your existing Business Intelligence (BI) tools.
-
Data Transformation Languages:
- SQL: A standard language for querying and manipulating databases, widely used in both ETL and ELT processes.
- PySpark: A Python library for large-scale data processing using Apache Spark, suitable for complex transformations in ETL pipelines.
- dbt (data build tool): A command-line tool that enables analytics and data teams to transform data in their warehouses more effectively, often used in ELT processes.
When choosing between ETL and ELT, it’s crucial to consider the following cautionary notes to ensure the selected approach aligns with your organization’s needs and capabilities:
Cautionary Notes for ETL
-
Complexity:
- Transformation Logic: ETL processes can become complex due to the need for extensive transformation logic before loading data.
- Maintenance: Complex ETL pipelines require ongoing maintenance and updates to handle changes in data sources and requirements.
-
Performance:
- Resource Intensive: ETL can be resource-intensive, especially for large datasets, as transformations are performed before loading.
- Latency: The transformation step can introduce latency, which may not be suitable for real-time analytics.
-
Data Quality:
- Validation: Ensure robust validation mechanisms are in place to maintain data quality throughout the transformation process.
- Consistency: Maintain consistency in data formats and structures to avoid discrepancies.
-
Scalability:
- Limited Scalability: ETL may not scale well for very large datasets, as transformations are performed on intermediate servers rather than in the target database.
Cautionary Notes for ELT
-
Data Storage:
- Storage Costs: ELT requires storing raw data in the target database, which can lead to increased storage costs.
- Data Management: Efficient data management practices are essential to handle the large volumes of raw data.
-
Processing Power:
- Dependency on Target System: ELT relies heavily on the processing power of the target database or cloud platform. Ensure the target system can handle the required transformations.
- Performance: Monitor the performance of the target system to avoid bottlenecks and ensure efficient data processing.
-
Data Quality:
- Post-Load Transformation: Ensure that post-load transformations are accurate and maintain data quality.
- Validation: Implement robust validation mechanisms to catch and correct errors in the transformed data.
-
Security:
- Data Encryption: Encrypt data both in transit and at rest to protect sensitive information.
- Access Control: Implement robust access controls to prevent unauthorized access to raw data.
-
Compliance:
- Regulatory Requirements: Ensure that the ELT process complies with relevant regulations and standards, such as GDPR or HIPAA.
- Audit Trails: Maintain audit trails to track data lineage and ensure compliance.
Conclusion
Data pipelines are indispensable for modern data architecture, enabling organizations to manage, process, and analyze vast amounts of data efficiently. By automating the flow of data from various sources to destinations, data pipelines enhance reliability, scalability, and efficiency. However, building and maintaining robust data pipelines requires careful planning, attention to data quality, security, and compliance, as well as continuous monitoring and optimization.
The choice between ETL and ELT depends on the specific needs and capabilities of an organization. ETL is well-suited for traditional data warehousing and scenarios requiring complex transformations and high data quality before loading. In contrast, ELT leverages the processing power of modern data warehouses and cloud platforms, making it ideal for big data analytics, real-time processing, and scalable data integration.