Introduction to Gradient Descent
Gradient Descent is a cornerstone optimization algorithm used in machine learning and deep learning to minimize functions and train models effectively. By iteratively adjusting parameters in the direction that reduces a cost function, gradient descent navigates through the landscape of a function to find its minima.
In this article, I’ll explain how gradient descent works, highlight the difference between local and global minima, discuss its shortcomings, and explore advanced variants that address these limitations.
How Gradient Descent Works
Gradient Descent minimizes a function by iteratively updating the parameter using the formula:
- : Current position of the parameter at iteration .
- : Learning rate, or step size.
- : Gradient of the function at .
The negative gradient () points toward the steepest descent, and the learning rate controls how far the algorithm moves at each step.
Example
Consider the function:
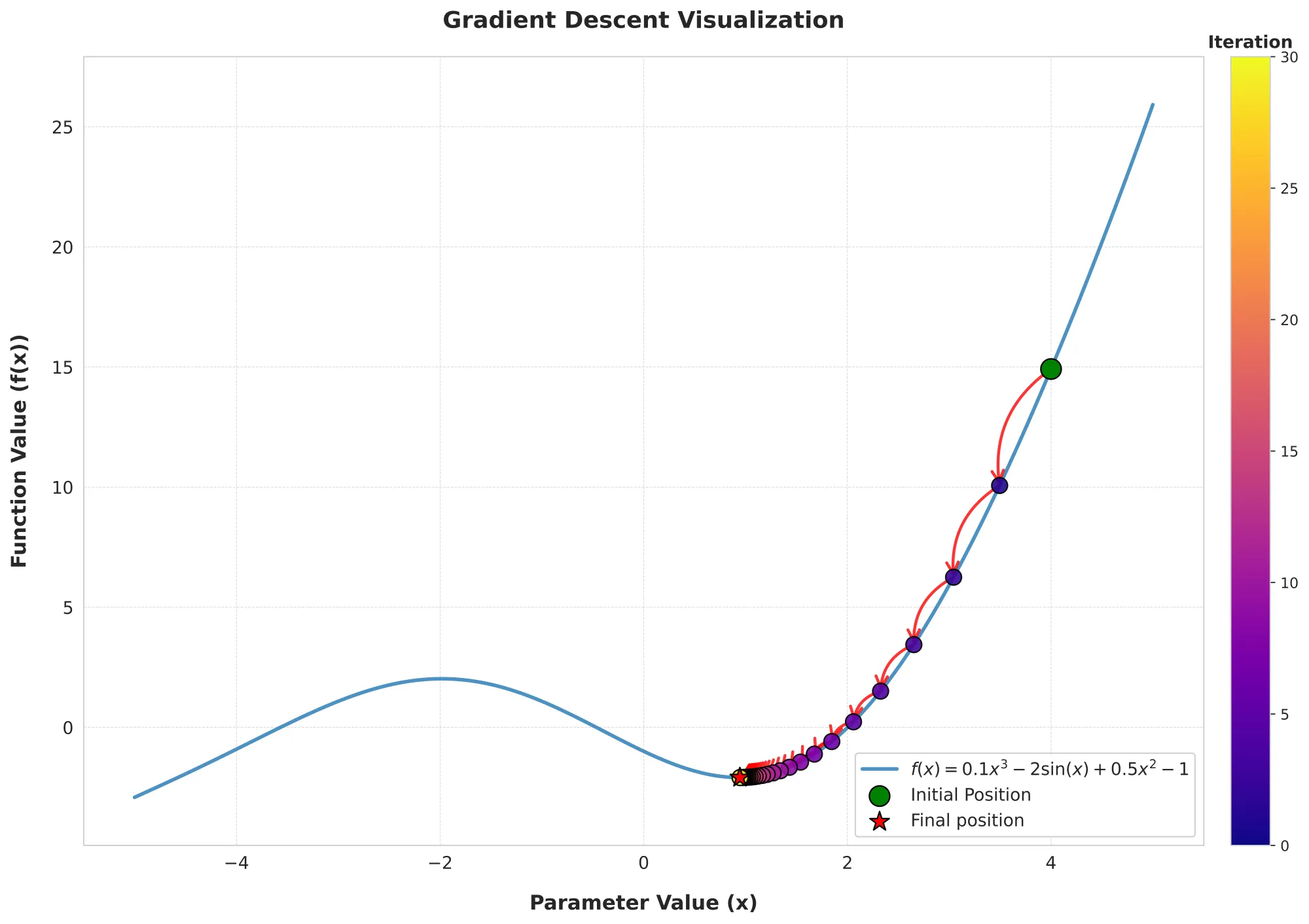
The gradient descent visualization demonstrates how the algorithm iteratively approaches a local minimum. Starting at an initial point (e.g., x = -2), it adjusts step by step, eventually converging to with .
Local vs. Global Minima
Local Minimum
A local minimum is a point where the function value is lower than that of nearby points, but it may not be the lowest point overall. In the example function, gradient descent converged to a local minimum because the function is non-convex.
Global Minimum
A global minimum is the absolute lowest point of the function over its entire domain. For non-convex functions, gradient descent may not find the global minimum due to the presence of multiple valleys.
Shortcomings of Gradient Descent
-
Local Minima and Saddle Points:
- Gradient descent may get trapped in a local minimum or saddle point (a flat region where the gradient is near zero but it’s neither a maximum nor a minimum).
-
Learning Rate Sensitivity:
- A small learning rate slows convergence.
- A large learning rate risks overshooting or diverging.
-
Non-Convex Functions:
- For complex, non-convex functions, the algorithm does not guarantee finding the global minimum.
-
Gradient Vanishing/Exploding:
- Gradients can become too small (vanish) or too large (explode), especially in deep learning scenarios.
Advanced Variants of Gradient Descent
Gradient descent has evolved into more advanced techniques to address its limitations, including issues with convergence speed, stability, and susceptibility to local minima. Below are some widely used advanced variants, explained in depth with their respective equations.
1. Stochastic Gradient Descent (SGD)
Description
Unlike standard gradient descent, which calculates the gradient using the entire dataset, Stochastic Gradient Descent (SGD) updates the model’s parameters using only a single randomly chosen data point (or a sample) per iteration. This makes it computationally efficient for large datasets.
Update Rule
Where:
- : Current parameters at iteration
- : Learning rate
- : Gradient computed for a single data point
Advantages
- Faster updates for large datasets.
- Introduces noise into the optimization process, which can help escape local minima.
Limitations
- Noisy convergence can lead to instability.
- May not converge to the exact minimum.
2. Mini-Batch Gradient Descent
Description
Mini-Batch Gradient Descent combines the benefits of standard gradient descent and SGD by using a small subset (mini-batch) of data points for each update.
Update Rule
Where:
- : Mini-batch of size
- Other terms are as defined in SGD.
Advantages
- Balances speed and convergence stability.
- Reduces memory usage compared to full-batch gradient descent.
- Averages out some noise from SGD.
3. Momentum
Description
Momentum adds a fraction of the previous parameter update to the current update, which accelerates convergence in the relevant direction and helps the algorithm bypass local minima or saddle points.
Update Rule
Where:
- : Velocity (cumulative moving average of gradients)
- : Momentum coefficient (typically )
- Other terms are as defined before.
Advantages
- Accelerates convergence, especially in ravines (areas with steep gradients in one dimension and shallow gradients in another).
- Helps avoid getting stuck in local minima.
4. RMSprop (Root Mean Square Propagation)
Description
RMSprop adjusts the learning rate for each parameter dynamically by maintaining a moving average of the squared gradients. This prevents the learning rate from becoming too small or too large.
Update Rule
Where:
- : Exponential moving average of squared gradients.
- : Gradient at step .
- : Small constant to prevent division by zero.
- : Smoothing constant (e.g., ).
Advantages
- Adapts the learning rate individually for each parameter.
- Suitable for non-stationary objectives and deep learning tasks.
5. Adam (Adaptive Moment Estimation)
Description
Adam combines the benefits of Momentum and RMSprop, maintaining both a moving average of the gradients and their squared values. It is one of the most widely used optimizers in deep learning.
Update Rules
- Compute biased moment estimates:
- Correct bias in the moment estimates:
- Update parameters:
Where:
- : Biased first and second moment estimates.
- : Exponential decay rates for the moments (default: and ).
- : Bias-corrected estimates.
- : Small constant (e.g.,) to prevent division by zero.
Advantages
- Combines the strengths of Momentum and RMSprop.
- Handles sparse gradients well.
- Robust default choice for most deep learning problems.
Comparison of Optimizers
| Optimizer | Key Feature | Use Case |
|---|---|---|
| SGD | Single data point updates | Large datasets |
| Mini-Batch | Subset of data updates | Balanced speed and stability |
| Momentum | Adds velocity to updates | Faster convergence, avoids local minima |
| RMSprop | Adaptive learning rate | Non-stationary objectives |
| Adam | Combines Momentum & RMSprop | General-purpose deep learning optimizer |
Summary of table
Each variant addresses specific challenges in gradient descent. The choice of optimizer depends on the problem’s nature, dataset size, and computational constraints.
Cautionary Notes - Gradient Descent in Practice
-
Local vs. Global Minima:
- Gradient descent does not guarantee finding the global minimum in non-convex functions. Techniques like initializing from multiple starting points or using global optimization algorithms (e.g., Simulated Annealing, Genetic Algorithms) may help.
-
Learning Rate Tuning:
- Always experiment with the learning rate. If convergence is too slow, increase it slightly; if it oscillates, reduce it. Techniques like learning rate schedules (decreasing the learning rate over time) can improve performance.
-
Feature Scaling:
- Ensure input features are normalized or standardized. Unscaled features can distort gradient calculations, leading to slow or incorrect convergence.
-
Visualization Helps:
- As seen in the plot, visualizing the function and optimization path helps understand convergence behavior and identify issues like getting stuck in a local minimum.
Conclusion
Gradient Descent is an essential tool in optimization, powering countless machine learning and deep learning algorithms. While it has its limitations—like susceptibility to local minima and sensitivity to learning rates—advanced variants such as Adam and RMSprop help address these challenges.
Understanding the trade-offs between local and global minima, and carefully tuning hyperparameters, are key to making the most of gradient descent. Visualizing the process, as shown in the reference plot, provides valuable insights into the algorithm’s behavior.